


Piyush Saggi
|
August 4, 2020
|
Resources
Why did we do this?
1. We found inconsistent reports online about which service is better. Each vendor claims to be better than everyone else. We wanted to find the truth.
2. Parmonic relies on speech-to-text (among other things) so we’re continuously interested, and invested, in keeping up with which service is performing better. We currently use two major engines. Fortunately, our algorithms have a tolerance threshold so currently available services perform pretty well for what we do. The main use case where the quality of the transcription is extremely important is closed captioning on videos for social media (which is now a feature in Parmonic).
3. Many of our current/potential clients are curious about this. Most online comparisons use esoteric terms like WER so we wanted to give readers a flavor of the truth in easy to understand terms.
Methodology
We picked a webinar recording and first got it transcribed by a human to arrive at what we call the ‘ground truth‘. Then we used various services to request automatic speech-to-text transcripts. This comparison is not statistically significant but we’re very confident this represents the current state of the market well. It’s easy to replicate so you can test on your own.
The speaker for this segment was a native speaker of American English. Audio quality in the video was very good. We wanted to minimize these two distractions (accent, audio quality).
Summary of Findings
1. In our sample, the speaker introduces other presenters. None of the automatic speech-to-text engines got the speakers’ names correct. This particular example included speakers of European descent and even that was an issue. If you’re from Pandora and your name is Neytiri, it’s definitely going to confuse the automated engines.
2. Automated engines occasionally err in transcribing common words if they can’t “hear” well. Fortunately, this is minor.
3. Automated engines have a really hard time getting punctuation right. This was quite pronounced across all the services.
4. Uncommon/technical terms are a challenge for automatic engines. One service transcribed the word “webinar” as “web and R”.
(However, there are ways to alleviate this with custom models and vocabularies which train the engines to recognize industry terms).
5. Even humans aren’t perfect. There was one error even in the human-generated transcript. While it was minor, it’s worth noting.
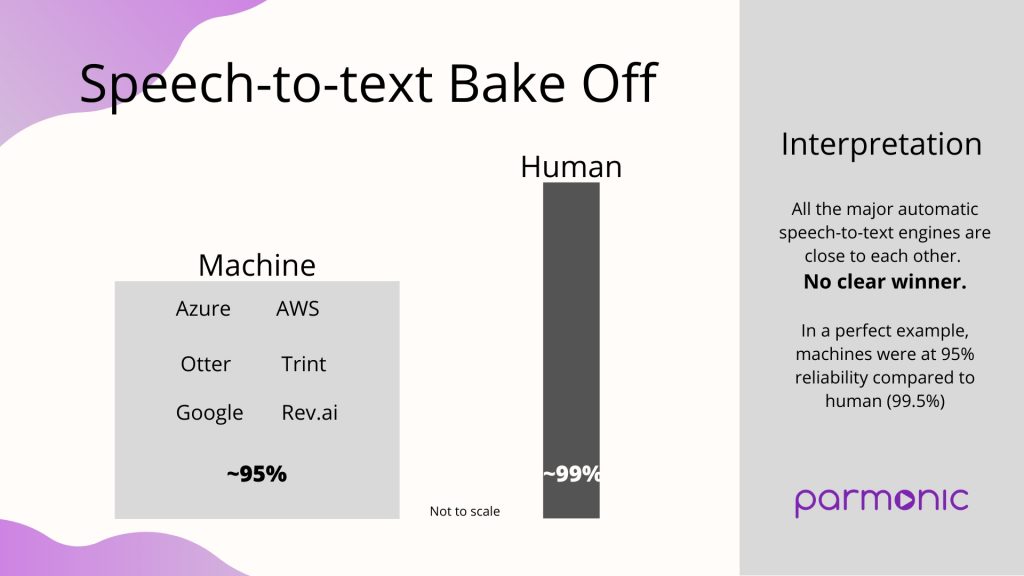
Results – Instead of reporting crazy stats, here’s our ‘common-sense’ evaluation. There are two clusters that speech-to-text services fall under.
Conclusion
Automatic speech-to-text has made really good progress in the past few years. Is it perfect yet? No. But it has made many other tasks easier. Depending on the use case, currently available services are just fine in some instances. And in other instances, you still need a human.
It’s important to evaluate based on the final use case and outcome.
While there are clear differences between the services as seen in this comparison, when we look at the overall results, our opinion is that these major services are all at about the same level. A small percentage improvement of one over the other is not significant for most purposes. We plan on doing a follow-up comparison in the future to see which service has improved over time. Improvement is a valuable metric to track.
We hope you found this comparison valuable. If you’re interested in learning more about snackifying videos and webinars using Parmonic, please reach out to us by clicking the button below. We'd love to get a demo set up for you!

